01. 优先队列知识
优先队列知识
1. 优先队列简介
优先队列(Priority Queue):一种特殊的队列。在优先队列中,元素被赋予优先级,当访问队列元素时,具有最高优先级的元素最先删除。
优先队列与普通队列最大的不同点在于 出队顺序。
- 普通队列的出队顺序跟入队顺序相关,符合「先进先出(First in, First out)」的规则。
- 优先队列的出队顺序跟入队顺序无关,优先队列是按照元素的优先级来决定出队顺序的。优先级高的元素优先出队,优先级低的元素后出队。优先队列符合 「最高级先出(First in, Largest out)」 的规则。
优先队列的示例图如下所示。
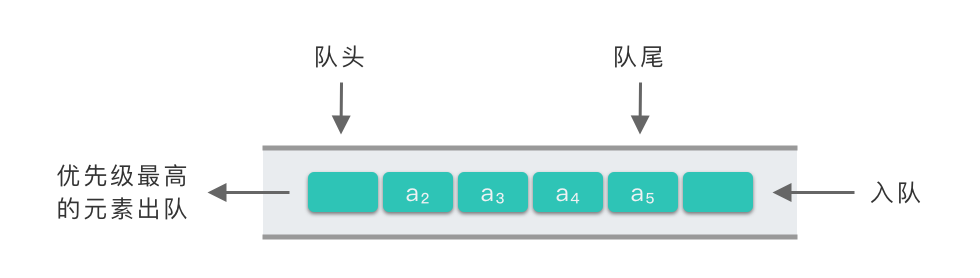
2. 优先队列的适用场景
优先队列的应用场景非常多,比如:
- 数据压缩:赫夫曼编码算法;
- 最短路径算法:Dijkstra 算法;
- 最小生成树算法:Prim 算法;
- 任务调度器:根据优先级执行系统任务;
- 事件驱动仿真:顾客排队算法;
- 排序问题:查找第 k 个最小元素。
很多语言都提供了优先级队列的实现。比如,Java 的 PriorityQueue,C++ 的 priority_queue 等。Python 中也可以通过 heapq 来实现优先队列。下面我们来讲解一下优先队列的实现。
3. 优先队列的实现方式
优先队列所涉及的基本操作跟普通队列差不多,主要是 「入队操作」 和 「出队操作」。
而优先队列的实现方式也有很多种,除了使用「数组(顺序存储)实现」与「链表(链式存储)实现」之外,我们最常用的是使用 **「二叉堆结构实现」**优先队列。以下是三种方案的介绍和总结。
- 数组(顺序存储)实现优先队列:入队操作直接插入到数组队尾,时间复杂度为 。出队操作需要遍历整个数组,找到优先级最高的元素,返回并删除该元素,时间复杂度为 。
- 链表(链式存储)实现优先队列:链表中的元素按照优先级排序,入队操作需要为待插入元素创建节点,并在链表中找到合适的插入位置,时间复杂度为 。出队操作直接返回链表队头元素,并删除队头元素,时间复杂度为 。
- 二叉堆结构实现优先队列:构建一个二叉堆结构,二叉堆按照优先级进行排序。入队操作就是将元素插入到二叉堆中合适位置,时间复杂度为 。出队操作则返回二叉堆中优先级最大节点并删除,时间复杂度也是 。
下面是三种结构实现的优先队列入队操作和出队操作的时间复杂度总结。
| 入队操作时间复杂度 | 出队操作(取出优先级最高的元素)时间复杂度 | |
|---|---|---|
| 堆 | ||
| 数组 | ||
| 链表 |
从上面的表格可以看出,使用「二叉堆」这种数据结构来实现优先队列是比较高效的。下面我们来讲解一下二叉堆实现的优先队列。
4. 二叉堆实现的优先队列
我们曾经在「01. 数组 - 02. 数组排序 - 07. 堆排序」中介绍过二叉堆,这里再简单介绍一下。
4.1 二叉堆的定义
二叉堆:符合以下两个条件之一的完全二叉树:
- 大顶堆:根节点值 ≥ 子节点值。
- 小顶堆:根节点值 ≤ 子节点值。
4.2 二叉堆的基本操作
二叉堆主要涉及两个基本操作:「堆调整方法」和「将数组构建为二叉堆方法」。
堆调整方法
heapAdjust:把移走了最大值元素以后的剩余元素组成的序列再构造为一个新的堆积。具体步骤如下:从根节点开始,自上而下地调整节点的位置,使其成为堆积。即把序号为 的节点与其左子树节点(序号为 )、右子树节点(序号为 )中值最大的节点交换位置。
因为交换了位置,使得当前节点的左右子树原有的堆积特性被破坏。于是,从当前节点的左右子树节点开始,自上而下继续进行类似的调整。
如此下去直到整棵完全二叉树成为一个大顶堆。
将数组构建为二叉堆方法(初始堆建立方法)
heapify:如果原始序列对应的完全二叉树(不一定是堆)的深度为 ,则从 层最右侧分支节点(序号为 )开始,初始时令 ,调用堆调整算法。
每调用一次堆调整算法,执行一次 ,直到 时,再调用一次,就把原始数组构建为了一个二叉堆。
4.3 优先队列的基本操作
在「3. 优先队列的实现方式」中我们已经提到过,优先队列所涉及的基本操作主要是 「入队操作」 和 「出队操作」。
- 入队操作
heappush:- 先将待插入元素 插入到数组 末尾。
- 如果完全二叉树的深度为 ,则从 层开始最右侧分支节点(序号为 )开始,初始时令 ,从下向上依次查找插入位置。
- 遇到 小于当前根节点时,将其插入到当前位置。否则继续向上寻找插入位置。
- 如果找到插入位置或者到达根位置,将 插入该位置。
- 出队操作
heappop:- 交换数组 首尾元素,此时 尾部就是值最大(优先级最高)的元素,将其从 中弹出,并保存起来。
- 弹出后,对 剩余元素调用堆调整算法,将其调整为大顶堆。
4.4 手写二叉堆实现优先队列
通过手写二叉堆的方式实现优先队列。主要实现了以下五种方法:
heapAdjust:将完全二叉树调整为二叉堆。heapify: 将数组构建为二叉堆方法(初始堆建立方法)。heappush:向堆中添加元素,也是优先队列的入队操作。heappop:删除堆顶元素,也是优先队列的出队操作,弹出优先队列中优先级最高的元素。heapSort:堆排序。
class Heapq:
# 堆调整方法:调整为大顶堆
def heapAdjust(self, nums: [int], index: int, end: int):
left = index * 2 + 1
right = left + 1
while left <= end:
# 当前节点为非叶子结点
max_index = index
if nums[left] > nums[max_index]:
max_index = left
if right <= end and nums[right] > nums[max_index]:
max_index = right
if index == max_index:
# 如果不用交换,则说明已经交换结束
break
nums[index], nums[max_index] = nums[max_index], nums[index]
# 继续调整子树
index = max_index
left = index * 2 + 1
right = left + 1
# 将数组构建为二叉堆
def heapify(self, nums: [int]):
size = len(nums)
# (size - 2) // 2 是最后一个非叶节点,叶节点不用调整
for i in range((size - 2) // 2, -1, -1):
# 调用调整堆函数
self.heapAdjust(nums, i, size - 1)
# 入队操作
def heappush(self, nums: list, value):
nums.append(value)
size = len(nums)
i = size - 1
# 寻找插入位置
while (i - 1) // 2 >= 0:
cur_root = (i - 1) // 2
# value 小于当前根节点,则插入到当前位置
if nums[cur_root] > value:
break
# 继续向上查找
nums[i] = nums[cur_root]
i = cur_root
# 找到插入位置或者到达根位置,将其插入
nums[i] = value
# 出队操作
def heappop(self, nums: list) -> int:
size = len(nums)
nums[0], nums[-1] = nums[-1], nums[0]
# 得到最大值(堆顶元素)然后调整堆
top = nums.pop()
if size > 0:
self.heapAdjust(nums, 0, size - 2)
return top
# 升序堆排序
def heapSort(self, nums: [int]):
self.heapify(nums)
size = len(nums)
for i in range(size):
nums[0], nums[size - i - 1] = nums[size - i - 1], nums[0]
self.heapAdjust(nums, 0, size - i - 2)
return nums
4.5 使用 heapq 模块实现优先队列
Python 中的 heapq 模块提供了优先队列算法。函数 heapq.heappush() 用于在队列 上插入一个元素。heapq.heappop() 用于在队列 上删除一个元素。
需要注意的是:heapq.heappop() 函数总是返回「最小的」的元素。所以我们在使用 heapq.heappush() 时,将优先级设置为负数,这样就使得元素可以按照优先级从高到低排序, 这个跟普通的按优先级从低到高排序的堆排序恰巧相反。这样做的目的是为了 heapq.heappop() 每次弹出的元素都是优先级最高的元素。
import heapq
class PriorityQueue:
def __init__(self):
self.queue = []
self.index = 0
def push(self, item, priority):
heapq.heappush(self.queue, (-priority, self.index, item))
self.index += 1
def pop(self):
return heapq.heappop(self.queue)[-1]
5. 优先队列的应用
5.1 滑动窗口最大值
5.1.1 题目链接
5.1.2 题目大意
描述:给定一个整数数组 ,再给定一个整数 ,表示为大小为 的滑动窗口从数组的最左侧移动到数组的最右侧。我们只能看到滑动窗口内的 个数字,滑动窗口每次只能向右移动一位。
要求:返回滑动窗口中的最大值。
说明:
- 。
- 。
- 。
示例:
输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7
输入:nums = [1], k = 1
输出:[1]
5.1.3 解题思路
暴力求解的话,需要使用二重循环遍历,其时间复杂度为 。根据题目给定的数据范围,肯定会超时。
我们可以使用优先队列来做。
思路 1:优先队列
- 初始的时候将前 个元素加入优先队列的二叉堆中。存入优先队列的是数组值与索引构成的元组。优先队列将数组值作为优先级。
- 然后滑动窗口从第 个元素开始遍历,将当前数组值和索引的元组插入到二叉堆中。
- 当二叉堆堆顶元素的索引已经不在滑动窗口的范围中时,即 时,不断删除堆顶元素,直到最大值元素的索引在滑动窗口的范围中。
- 将最大值加入到答案数组中,继续向右滑动。
- 滑动结束时,输出答案数组。
思路 1:代码
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
size = len(nums)
q = [(-nums[i], i) for i in range(k)]
heapq.heapify(q)
res = [-q[0][0]]
for i in range(k, size):
heapq.heappush(q, (-nums[i], i))
while q[0][1] <= i - k:
heapq.heappop(q)
res.append(-q[0][0])
return res
思路 1:复杂度分析
- 时间复杂度:。
- 空间复杂度:。
5.2 前 K 个高频元素
5.2.1 题目链接
5.2.2 题目大意
描述:给定一个整数数组 和一个整数 。
要求:返回出现频率前 高的元素。可以按任意顺序返回答案。
说明:
- 。
- 的取值范围是 。
- 题目数据保证答案唯一,换句话说,数组中前 个高频元素的集合是唯一的。
示例:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
输入: nums = [1], k = 1
输出: [1]
5.2.3 解题思路
思路 1:哈希表 + 优先队列
- 使用哈希表记录下数组中各个元素的频数。
- 然后将哈希表中的元素去重,转换为新数组。时间复杂度 ,空间复杂度 。
- 使用二叉堆构建优先队列,优先级为元素频数。此时堆顶元素即为频数最高的元素。时间复杂度 ,空间复杂度 。
- 将堆顶元素加入到答案数组中,进行出队操作。时间复杂度 。
- 出队操作:交换堆顶元素与末尾元素,将末尾元素已移出堆。继续调整大顶堆。
- 不断重复第 4 步,直到 次结束。调整 次的时间复杂度 。
思路 1:代码
class Heapq:
# 堆调整方法:调整为大顶堆
def heapAdjust(self, nums: [int], nums_dict, index: int, end: int):
left = index * 2 + 1
right = left + 1
while left <= end:
# 当前节点为非叶子结点
max_index = index
if nums_dict[nums[left]] > nums_dict[nums[max_index]]:
max_index = left
if right <= end and nums_dict[nums[right]] > nums_dict[nums[max_index]]:
max_index = right
if index == max_index:
# 如果不用交换,则说明已经交换结束
break
nums[index], nums[max_index] = nums[max_index], nums[index]
# 继续调整子树
index = max_index
left = index * 2 + 1
right = left + 1
# 将数组构建为二叉堆
def heapify(self, nums: [int], nums_dict):
size = len(nums)
# (size - 2) // 2 是最后一个非叶节点,叶节点不用调整
for i in range((size - 2) // 2, -1, -1):
# 调用调整堆函数
self.heapAdjust(nums, nums_dict, i, size - 1)
# 入队操作
def heappush(self, nums: list, nums_dict, value):
nums.append(value)
size = len(nums)
i = size - 1
# 寻找插入位置
while (i - 1) // 2 >= 0:
cur_root = (i - 1) // 2
# value 小于当前根节点,则插入到当前位置
if nums_dict[nums[cur_root]] > nums_dict[value]:
break
# 继续向上查找
nums[i] = nums[cur_root]
i = cur_root
# 找到插入位置或者到达根位置,将其插入
nums[i] = value
# 出队操作
def heappop(self, nums: list, nums_dict) -> int:
size = len(nums)
nums[0], nums[-1] = nums[-1], nums[0]
# 得到最大值(堆顶元素)然后调整堆
top = nums.pop()
if size > 0:
self.heapAdjust(nums, nums_dict, 0, size - 2)
return top
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
# 统计元素频数
nums_dict = dict()
for num in nums:
if num in nums_dict:
nums_dict[num] += 1
else:
nums_dict[num] = 1
# 使用 set 方法去重,得到新数组
new_nums = list(set(nums))
size = len(new_nums)
heap = Heapq()
queue = []
for num in new_nums:
heap.heappush(queue, nums_dict, num)
res = []
for i in range(k):
res.append(heap.heappop(queue, nums_dict))
return res
思路 1:复杂度分析
- 时间复杂度:。
- 空间复杂度:。