5.8 并查集
5.8 并查集
---1. 并查集简介
1.1 并查集的定义
并查集(Union Find):一种高效的数据结构,常用于处理若干不相交集合(Disjoint Sets)的合并与查询操作。不相交集合指的是元素互不重叠的集合族。
并查集主要支持两类核心操作:
- 合并(Union):将两个不同的集合合并为一个集合。
- 查找(Find):确定某个元素属于哪个集合,通常返回该集合的「代表元素」。
简而言之,并查集用于高效地管理集合的合并与成员归属查询。
- 并查集中的「集」指的是不相交的集合,即元素互不重复、互不重叠的若干集合。
- 并查集中的「并」指的是集合的并集操作,即将两个不同的集合合并为一个更大的集合。合并操作如下:
{1, 3, 5, 7} U {2, 4, 6, 8} = {1, 2, 3, 4, 5, 6, 7, 8}- 并查集中的「查」操作,主要用于判断两个元素是否属于同一个集合。
如果只是判断某个元素是否在集合中,直接用 Python 的 set 类型即可。但如果要 高效判断两个元素是否属于同一集合,set 就不适合了,因为它只能判断单个元素是否存在,无法快速判断两个元素是否在同一个集合里,往往需要遍历所有集合,效率很低。此时,就需要用专门的并查集结构,才能高效地支持集合的合并和连通性查询。
基于上述需求,并查集通常支持以下核心操作接口:
- 合并
union(x, y):将包含元素 和 的两个集合合并为一个集合。 - 查找
find(x):查找元素 所在集合的代表元素(根节点)。 - 连通性判断
is_connected(x, y):判断元素 和 是否属于同一个集合。
1.2 并查集的两种实现思路
并查集常见的两种实现方式分别侧重于不同操作的效率:一种是「快速查询」——基于数组结构,另一种是「快速合并」——基于森林结构。
1.2.1 快速查询:基于数组实现
当我们更关注查询操作的效率时,可以采用基于数组的实现方式。
在这种实现中,使用一个数组来表示每个元素所属的集合。数组的下标代表元素本身,数组的值()表示该元素所在集合的编号。具体操作如下:
- 初始化:将每个元素的集合编号设为其自身的下标,即每个元素自成一个集合。
- 合并操作:将一个集合中的所有元素的 修改为另一个集合的 ,从而实现集合的合并。这样,合并后同一集合内所有元素的 都相同。
- 查找操作:直接比较两个元素的 是否相同,如果相同则属于同一集合,否则属于不同集合。
举例说明,假设有集合 ,初始化如下:
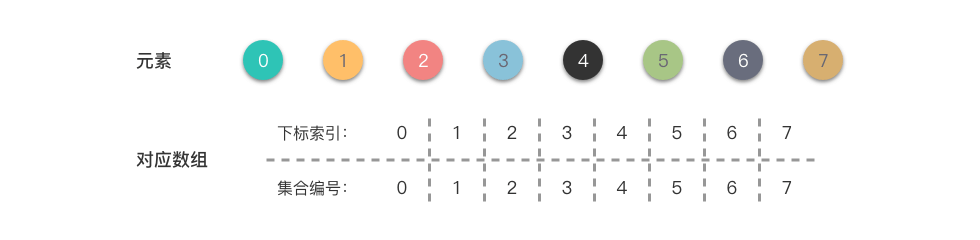
如上图所示,数组下标即为元素编号,初始时每个元素单独成集。
经过若干次合并操作后,例如合并成 ,结果如下:
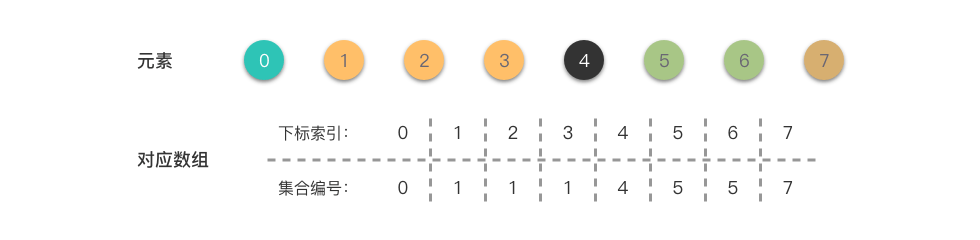
可以看到,、、 的 相同,说明它们属于同一集合; 和 也同理。
这种实现方式下,查询操作的时间复杂度为 ,但合并操作的时间复杂度为 (每次合并都需遍历整个数组)。因此,虽然查询极快,但合并效率较低,实际应用中较少采用。
- 基于「快速查询」思路的并查集代码如下:
class UnionFind:
def __init__(self, n):
"""
初始化并查集,将每个元素的集合编号初始化为其自身下标。
:param n: 元素总数
"""
self.ids = [i for i in range(n)] # ids[i] 表示元素 i 所在集合的编号
def find(self, x):
"""
查找元素 x 所在集合的编号。
:param x: 元素编号
:return: x 所在集合的编号
"""
return self.ids[x]
def union(self, x, y):
"""
合并包含元素 x 和 y 的两个集合。
:param x: 元素 x
:param y: 元素 y
:return: 如果 x 和 y 原本就在同一集合,返回 False;否则合并并返回 True
"""
x_id = self.find(x)
y_id = self.find(y)
if x_id == y_id:
# x 和 y 已经在同一个集合,无需合并
return False
# 遍历所有元素,将属于 y_id 集合的元素编号改为 x_id,实现合并
for i in range(len(self.ids)):
if self.ids[i] == y_id:
self.ids[i] = x_id
return True
def is_connected(self, x, y):
"""
判断元素 x 和 y 是否属于同一个集合。
:param x: 元素 x
:param y: 元素 y
:return: 如果属于同一集合返回 True,否则返回 False
"""
return self.find(x) == self.find(y)1.2.2 快速合并:基于森林实现
在「快速查询」的实现方式中,合并操作效率较低,因此我们需要优化合并操作的性能。
为此,可以采用「森林结构」来实现并查集。具体做法是:用若干棵树(即森林)来表示所有集合,每棵树代表一个集合,树中的每个节点对应一个元素,树的根节点即为该集合的代表元素。
注意:与常规树结构(父节点指向子节点)不同,基于森林的并查集中,每个节点都指向其父节点。
我们可以用一个数组 来维护森林结构,其中 表示元素 的父节点编号。也就是说, 通过 指向其父节点。
- 初始化:令 ,即每个元素自成一个集合,自己是自己的根节点。
- 合并操作:将两个集合的根节点相连,例如令 ,即把 所在集合合并到 所在集合。
- 查找操作:从某个元素出发,沿着 数组不断查找其父节点,直到找到根节点。如果两个元素的根节点相同,则它们属于同一集合,否则属于不同集合。
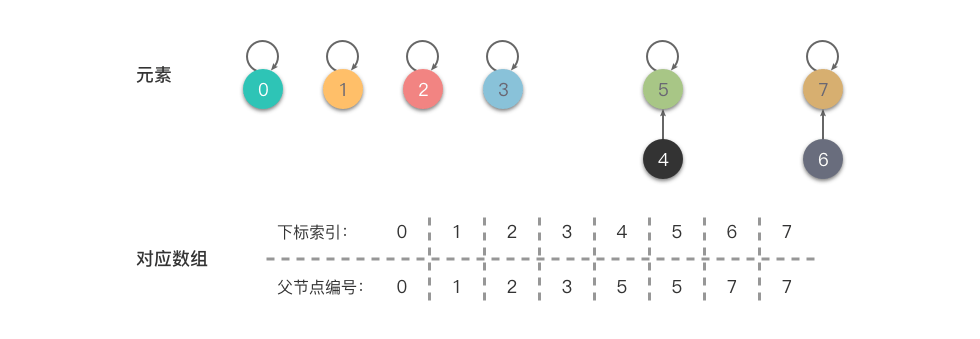
举例说明,假设有集合 ,初始化时如下图:
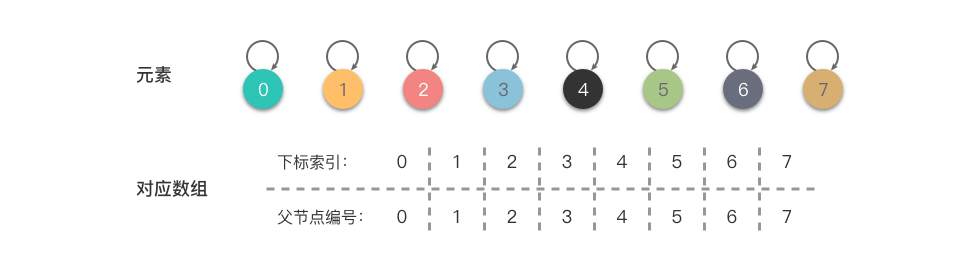
从上图中可以看出: 数组的每个下标索引值对应一个元素的集合编号,代表着每个元素属于一个集合。
接下来,依次执行 union(4, 5)、union(6, 7)、union(4, 7),最终集合变为 ,具体步骤如下:
- 合并 :将 的根节点指向 ,即 。
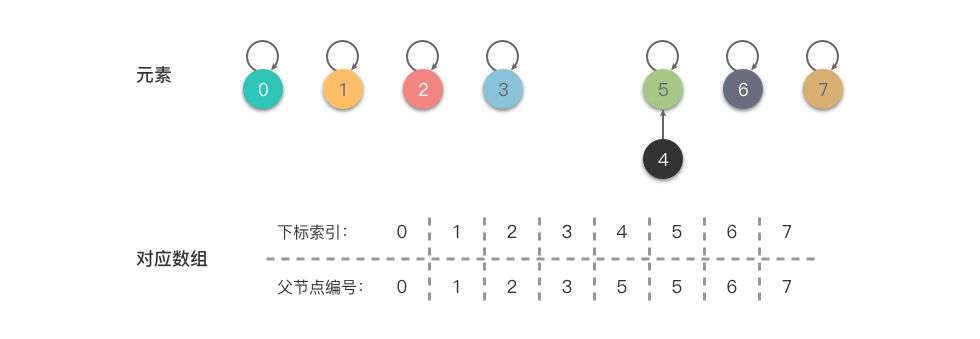
- 合并 :将 的根节点指向 ,即 。
- 合并 :将 的根节点(即 )指向 ,即 。
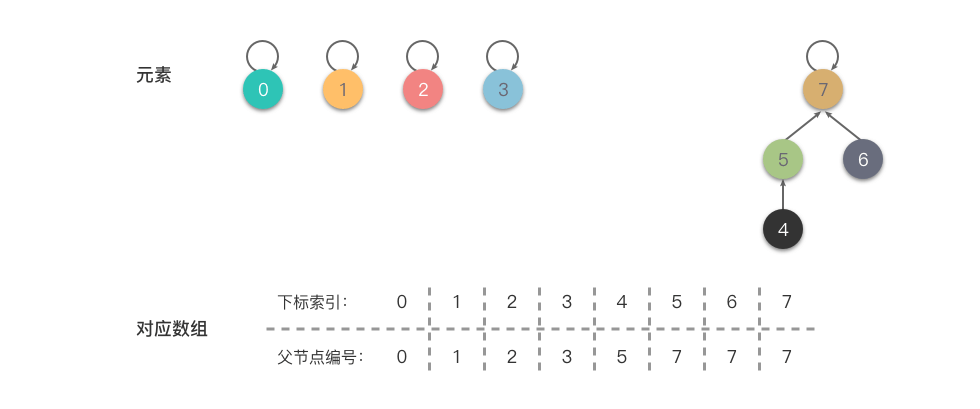
可以看到,经过上述合并后,、、、 的根节点编号都为 ,说明它们已经属于同一个集合。
- 基于「快速合并」思想的并查集代码如下:
class UnionFind:
def __init__(self, n):
"""
初始化并查集,将每个元素的父节点初始化为自身
:param n: 元素个数
"""
self.fa = [i for i in range(n)] # fa[x] 表示 x 的父节点,初始时每个节点自成一个集合
def find(self, x):
"""
查找元素 x 所在集合的根节点(代表元)
:param x: 待查找的元素
:return: x 所在集合的根节点编号
"""
# 循环查找父节点,直到找到根节点(fa[x] == x)
while self.fa[x] != x:
x = self.fa[x]
return x
def union(self, x, y):
"""
合并 x 和 y 所在的两个集合
:param x: 元素 x
:param y: 元素 y
:return: 如果 x 和 y 原本属于同一集合,返回 False;否则合并并返回 True
"""
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
# x 和 y 已经在同一个集合中,无需合并
return False
self.fa[root_x] = root_y # 将 x 的根节点连接到 y 的根节点
return True
def is_connected(self, x, y):
"""
判断 x 和 y 是否属于同一个集合
:param x: 元素 x
:param y: 元素 y
:return: 如果属于同一集合返回 True,否则返回 False
"""
return self.find(x) == self.find(y)2. 路径压缩
当集合规模较大或树结构极度不平衡时,单纯依赖「快速合并」的并查集实现效率较低。在最坏情况下,树会退化为一条链,此时单次查找操作的时间复杂度为 ,如下图所示:
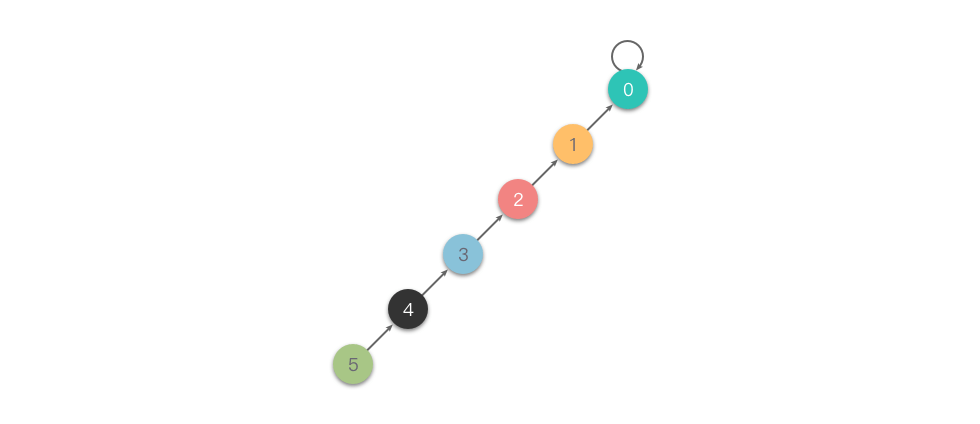
为了提升效率、避免上述最坏情况,常用的优化手段是「路径压缩」。
路径压缩(Path Compression):在查找根节点的过程中,将路径上经过的所有节点尽量直接挂到根节点下,从而显著降低树的高度,提高后续操作的效率。
路径压缩主要有两种常见实现方式:一种是「隔代压缩」,另一种是「完全压缩」。
2.1 隔代压缩
隔代压缩:在查找操作时,每次将当前节点直接连接到其父节点的父节点(即跳过一层),通过不断重复这一过程,有效降低树的高度,从而提升并查集的查找效率。
如下图所示,展示了隔代压缩的过程:
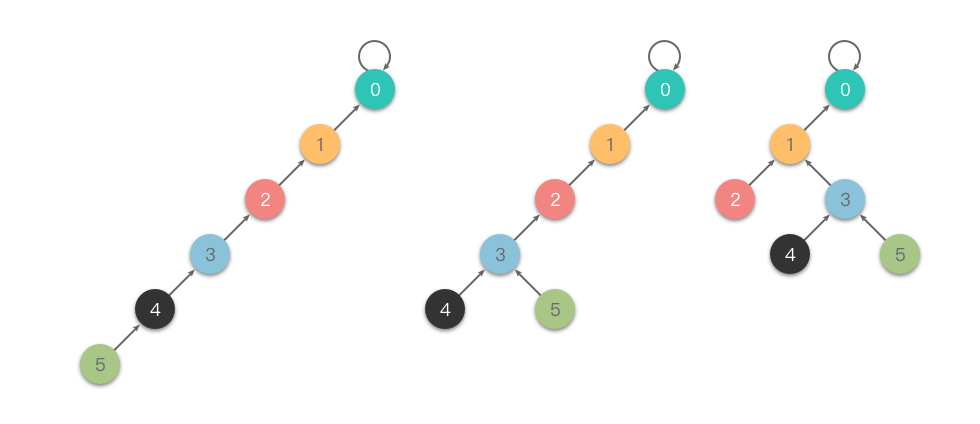
隔代压缩的查找代码如下:
def find(self, x):
"""
查找元素 x 所在集合的根节点(带隔代路径压缩)
:param x: 待查找的元素
:return: x 所在集合的根节点编号
"""
while self.fa[x] != x:
# 将 x 的父节点直接指向其祖父节点,实现隔代压缩
self.fa[x] = self.fa[self.fa[x]]
x = self.fa[x] # 继续向上查找
return x # 返回根节点编号2.2 完全压缩
完全压缩:在查找操作时,将从当前节点到根节点路径上的所有节点的父节点都直接指向根节点,从而极大地降低树的高度。这样,后续对这些节点的查找都能一步到达根节点,显著提升效率。
与「隔代压缩」相比,「完全压缩」能够更彻底地扁平化树结构。如下图所示:
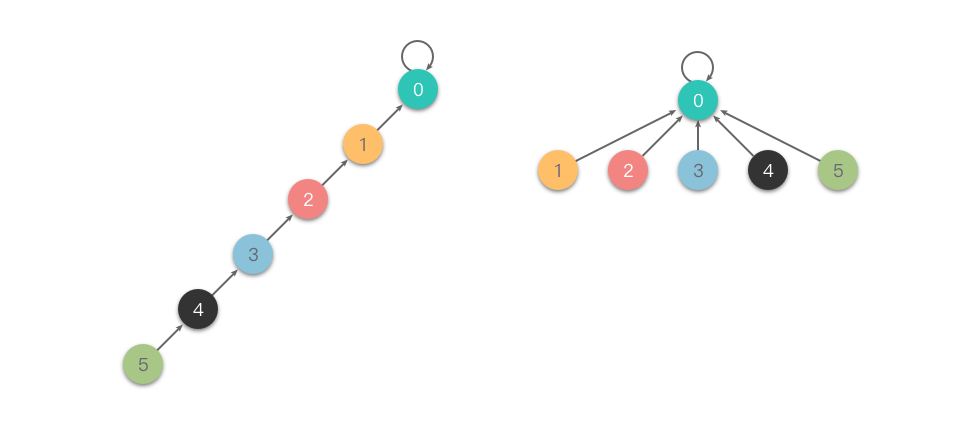
完全压缩的查找代码如下:
def find(self, x):
"""
查找元素 x 所在集合的根节点(带完全路径压缩)
:param x: 待查找的元素
:return: x 所在集合的根节点编号
"""
if self.fa[x] != x: # 如果 x 不是根节点,递归查找其父节点
self.fa[x] = self.find(self.fa[x]) # 路径压缩:将 x 直接连接到根节点
return self.fa[x] # 返回根节点编号3. 按秩合并
虽然路径压缩能够有效降低树的高度,但它只在查找操作时生效,且仅影响当前查找路径上的节点。因此,如果仅依赖路径压缩,整个并查集的结构仍可能出现较高的树。为进一步优化并查集的结构,常用的另一种方法是「按秩合并」。
按秩合并(Union By Rank):在每次合并操作时,总是将「秩」较小的树的根节点连接到「秩」较大的树的根节点下。
这里的「秩」可以有两种常见定义:一种是树的深度,另一种是集合的大小(即节点个数)。无论采用哪种定义,秩的信息都只需记录在每棵树的根节点上。
按秩合并主要有两种实现方式:一种是「按深度合并」,另一种是「按大小合并」。
3.1 按深度合并
按深度合并(Union By Rank):每次合并时,将「深度」较小的树的根节点指向「深度」较大的树的根节点。
具体做法是,使用一个数组 记录每个根节点对应的树的深度(非根节点的 值无实际意义,仅根节点有效)。
初始化时,所有元素的 值设为 。合并时,比较两个集合根节点的 ,将 较小的根节点指向 较大的根节点。如果两棵树深度相同,任选一方作为新根,并将其 加 。
如下图所示为「按深度合并」的示意:
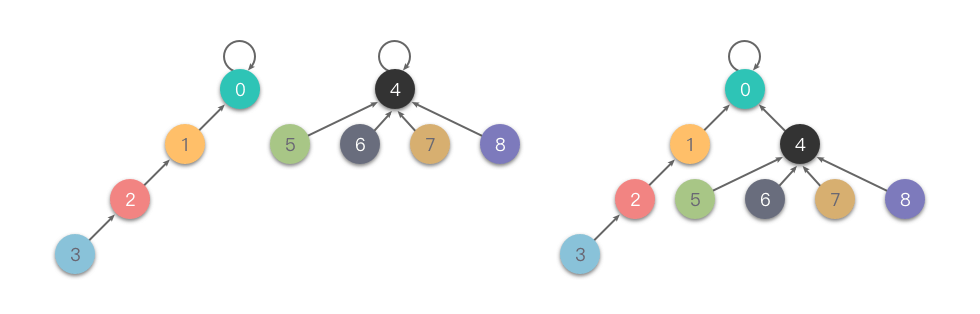
按深度合并的实现代码如下:
class UnionFind:
def __init__(self, n):
"""
初始化并查集
:param n: 元素个数
"""
self.fa = [i for i in range(n)] # fa[i] 表示元素 i 的父节点,初始时每个元素自成一个集合
self.rank = [1 for _ in range(n)] # rank[i] 表示以 i 为根的树的深度,初始为 1
def find(self, x):
"""
查找元素 x 所在集合的根节点(带路径压缩,隔代压缩)
:param x: 待查找的元素
:return: x 所在集合的根节点编号
"""
while self.fa[x] != x: # 如果 x 不是根节点,继续查找其父节点
self.fa[x] = self.fa[self.fa[x]]# 路径压缩:将 x 直接连接到祖父节点,实现隔代压缩
x = self.fa[x]
return x # 返回根节点编号
def union(self, x, y):
"""
合并操作:将 x 和 y 所在的集合合并
:param x: 元素 x
:param y: 元素 y
:return: 如果合并成功返回 True,如果已在同一集合返回 False
"""
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y: # x 和 y 已经在同一个集合
return False
# 按秩合并:将深度较小的树合并到深度较大的树下
if self.rank[root_x] < self.rank[root_y]:
self.fa[root_x] = root_y # x 的根节点连接到 y 的根节点
elif self.rank[root_x] > self.rank[root_y]:
self.fa[root_y] = root_x # y 的根节点连接到 x 的根节点
else:
self.fa[root_x] = root_y # 深度相同,任选一方作为新根
self.rank[root_y] += 1 # 新根的深度加 1
return True
def is_connected(self, x, y):
"""
查询操作:判断 x 和 y 是否属于同一个集合
:param x: 元素 x
:param y: 元素 y
:return: 如果属于同一集合返回 True,否则返回 False
"""
return self.find(x) == self.find(y)3.2 按大小合并
按大小合并(Union By Size):此处的「大小」指的是集合中节点的数量。每次合并时,总是将节点数较少的集合的根节点指向节点数较多的集合的根节点,从而有效控制树的高度。
具体做法是,使用一个数组 记录每个根节点所代表集合的节点个数(对于非根节点, 的值无实际意义,仅根节点的 有效)。
初始化时,所有元素各自为一个集合,因此 均为 。合并操作时,先分别找到两个元素的根节点,比较它们的 ,将较小集合的根节点连接到较大集合的根节点,并更新新根节点的 。
如下图所示为按大小合并的示意:
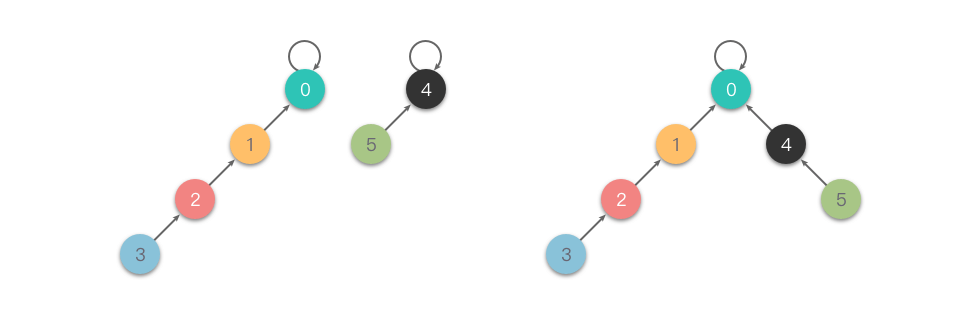
按大小合并的实现代码如下:
class UnionFind:
def __init__(self, n):
"""
初始化并查集
:param n: 元素个数
"""
self.fa = [i for i in range(n)] # fa[i] 表示元素 i 的父节点,初始时每个元素自成一个集合
self.size = [1 for _ in range(n)] # size[i] 表示以 i 为根的集合的元素个数,初始为 1
def find(self, x):
"""
查找元素 x 所在集合的根节点(带隔代路径压缩)
:param x: 待查找的元素
:return: x 所在集合的根节点编号
"""
while self.fa[x] != x:
self.fa[x] = self.fa[self.fa[x]] # 隔代路径压缩,将 x 直接连接到祖父节点
x = self.fa[x]
return x
def union(self, x, y):
"""
合并操作:将 x 和 y 所在的集合合并(按集合大小合并)
:param x: 元素 x
:param y: 元素 y
:return: 如果合并成功返回 True,如果已在同一集合返回 False
"""
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return False # x 和 y 已经在同一个集合,无需合并
# 按集合大小合并:小集合合并到大集合
if self.size[root_x] < self.size[root_y]:
self.fa[root_x] = root_y
self.size[root_y] += self.size[root_x]
elif self.size[root_x] > self.size[root_y]:
self.fa[root_y] = root_x
self.size[root_x] += self.size[root_y]
else:
# 集合大小相等,任选一方作为新根
self.fa[root_x] = root_y
self.size[root_y] += self.size[root_x]
return True
def is_connected(self, x, y):
"""
查询操作:判断 x 和 y 是否属于同一个集合
:param x: 元素 x
:param y: 元素 y
:return: 如果属于同一集合返回 True,否则返回 False
"""
return self.find(x) == self.find(y)3.3 按秩合并的注意点
很多同学会疑惑:再路径压缩时,为什么不用更新 或 ?
其实,路径压缩后, 和 已经不再代表真实的树高或集合大小。它们只是合并时用来比较「谁大谁小」的辅助标记,只在合并操作时起作用。
换句话说,我们不需要关心每个节点的真实深度或集合元素个数,只要 或 能正确反映两个集合的相对大小即可。
此外,路径压缩只会让树变矮, 或 只会增加,不会减少。因此,它们足以作为合并时的比较依据,无需在路径压缩时维护真实值。
4. 并查集的算法分析
- 时间复杂度:在同时使用「路径压缩」和「按秩合并」优化后,合并(union)和查找(find)操作的均摊时间复杂度非常接近 。更精确地说, 次操作的总时间复杂度为 ,其中 是阿克曼函数的反函数,增长极其缓慢,实际应用中可视为常数。
- 空间复杂度:主要由数组 (父节点数组)构成,如果采用「按秩合并」优化,还需额外的 或 数组。整体空间复杂度为 ,其中 为元素个数。
5. 并查集的推荐实现方式
结合实际刷题和主流经验,推荐并查集的实现策略如下:优先采用「隔代压缩」优化,一般情况下无需引入「按秩合并」。
这种做法的优势在于代码简洁、易于实现,同时性能表现也非常优秀。只有在遇到性能瓶颈时,再考虑引入「按秩合并」进一步优化。
此外,如果题目需要支持查询集合数量或集合内元素个数等功能,可根据具体需求对实现进行适当扩展。
采用「隔代压缩」且不使用「按秩合并」的并查集实现代码:
class UnionFind:
def __init__(self, n): # 初始化
self.fa = [i for i in range(n)] # 每个元素的集合编号初始化为数组 fa 的下标索引
def find(self, x): # 查找元素根节点的集合编号内部实现方法
while self.fa[x] != x: # 递归查找元素的父节点,直到根节点
self.fa[x] = self.fa[self.fa[x]] # 隔代压缩优化
x = self.fa[x]
return x # 返回元素根节点的集合编号
def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另一个集合的树根节点
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y: # x 和 y 的根节点集合编号相同,说明 x 和 y 已经同属于一个集合
return False
self.fa[root_x] = root_y # x 的根节点连接到 y 的根节点上,成为 y 的根节点的子节点
return True
def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
return self.find(x) == self.find(y)使用「隔代压缩」,使用「按秩合并」的并查集最终实现代码:
class UnionFind:
def __init__(self, n): # 初始化
self.fa = [i for i in range(n)] # 每个元素的集合编号初始化为数组 fa 的下标索引
self.rank = [1 for i in range(n)] # 每个元素的深度初始化为 1
def find(self, x): # 查找元素根节点的集合编号内部实现方法
while self.fa[x] != x: # 递归查找元素的父节点,直到根节点
self.fa[x] = self.fa[self.fa[x]] # 隔代压缩优化
x = self.fa[x]
return x # 返回元素根节点的集合编号
def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另一个集合的树根节点
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y: # x 和 y 的根节点集合编号相同,说明 x 和 y 已经同属于一个集合
return False
if self.rank[root_x] < self.rank[root_y]: # x 的根节点对应的树的深度 小于 y 的根节点对应的树的深度
self.fa[root_x] = root_y # x 的根节点连接到 y 的根节点上,成为 y 的根节点的子节点
elif self.rank[root_x] > self.rank[root_y]: # x 的根节点对应的树的深度 大于 y 的根节点对应的树的深度
self.fa[root_y] = root_x # y 的根节点连接到 x 的根节点上,成为 x 的根节点的子节点
else: # x 的根节点对应的树的深度 等于 y 的根节点对应的树的深度
self.fa[root_x] = root_y # 向任意一方合并即可
self.rank[root_y] += 1 # 因为层数相同,被合并的树必然层数会 +1
return True
def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
return self.find(x) == self.find(y)6. 并查集的应用
并查集通常用来求解不同元素之间的关系问题,比如判断两个人是否是亲戚关系、两个点之间时候存在至少一条路径连接。或者用来求解集合的个数、集合中元素的个数等等。
6.1 等式方程的可满足性
6.1.1 题目链接
6.1.2 题目大意
描述:给定一个由字符串方程组成的数组 ,每个字符串方程 的长度为 ,有以下两种形式组成:a==b 或 a!=b。 和 是小写字母,表示单字母变量名。
要求:判断所有的字符串方程是否能同时满足,如果能同时满足,返回 ,否则返回 。
说明:
- 。
- 。
- 和 是小写字母。
- 要么是
'=',要么是'!'。 - 是
'='。
示例:
输入:["a==b","b!=a"]
输出:False
解释:如果我们指定,a = 1 且 b = 1
那么可以满足第一个方程,但无法满足第二个方程。
没有办法分配变量同时满足这两个方程。6.1.3 解题思路
由于字符串方程仅包含 == 或 != 两种形式,我们可以将所有等式(==)的变量归为同一个集合,然后再检查所有不等式(!=)的变量是否被错误地划分到了同一集合中。如果出现这种情况,则说明方程组无法同时满足。
具体步骤如下:
- 首先遍历所有等式方程,将等式两侧的变量通过并查集合并到同一个集合中。
- 然后遍历所有不等式方程,判断不等式两侧的变量是否已经在同一个集合中。如果在同一集合,则说明存在矛盾,返回 ;如果所有不等式都检查无冲突,则返回 。
6.1.4 代码
class UnionFind:
def __init__(self, n): # 初始化
self.fa = [i for i in range(n)] # 每个元素的集合编号初始化为数组 fa 的下标索引
def find(self, x): # 查找元素根节点的集合编号内部实现方法
while self.fa[x] != x: # 递归查找元素的父节点,直到根节点
self.fa[x] = self.fa[self.fa[x]] # 隔代压缩优化
x = self.fa[x]
return x # 返回元素根节点的集合编号
def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另一个集合的树根节点
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y: # x 和 y 的根节点集合编号相同,说明 x 和 y 已经同属于一个集合
return False
self.fa[root_x] = root_y # x 的根节点连接到 y 的根节点上,成为 y 的根节点的子节点
return True
def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
return self.find(x) == self.find(y)
class Solution:
def equationsPossible(self, equations: List[str]) -> bool:
union_find = UnionFind(26)
for eqation in equations:
if eqation[1] == "=":
index1 = ord(eqation[0]) - 97
index2 = ord(eqation[3]) - 97
union_find.union(index1, index2)
for eqation in equations:
if eqation[1] == "!":
index1 = ord(eqation[0]) - 97
index2 = ord(eqation[3]) - 97
if union_find.is_connected(index1, index2):
return False
return True练习题目
参考资料
- 【博文】并查集 - OI Wiki
- 【博文】并查集 - LeetBook - 力扣
- 【博文】并查集概念及用法分析 - 掘金
- 【博文】数据结构之并查集 - 端碗吹水的技术博客
- 【博文】并查集复杂度 - OI Wiki
- 【题解】使用并查集处理不相交集合问题(Java、Python) - 等式方程的可满足性 - 力扣
- 【书籍】算法训练营 - 陈小玉 著
- 【书籍】算法 第 4 版 - 谢路云 译
- 【书籍】算法竞赛进阶指南 - 李煜东 著
- 【书籍】算法竞赛入门经典:训练指南 - 刘汝佳,陈锋 著