0158. 用 Read4 读取 N 个字符 II - 多次调用
大约 5 分钟
--- 
0158. 用 Read4 读取 N 个字符 II - 多次调用
- 标签:数组、交互、模拟
- 难度:困难
题目链接
题目大意
描述:
给定一个文件 file,并且该文件只能通过给定的 read4 方法来读取,请实现一个方法使其能够使 read 读取 个字符。
注意:你的 read 方法可能会被调用多次。
read4 的定义:
read4API 从文件中读取 4 个连续的字符,然后将这些字符写入缓冲区数组buf4。- 返回值是读取的实际字符数。
- 请注意,
read4()有其自己的文件指针,类似于 C 中的FILE *fp。
参数类型: char[] buf4
返回类型: int注意: buf4[] 是目标缓存区不是源缓存区,read4 的返回结果将会复制到 buf4[] 当中。
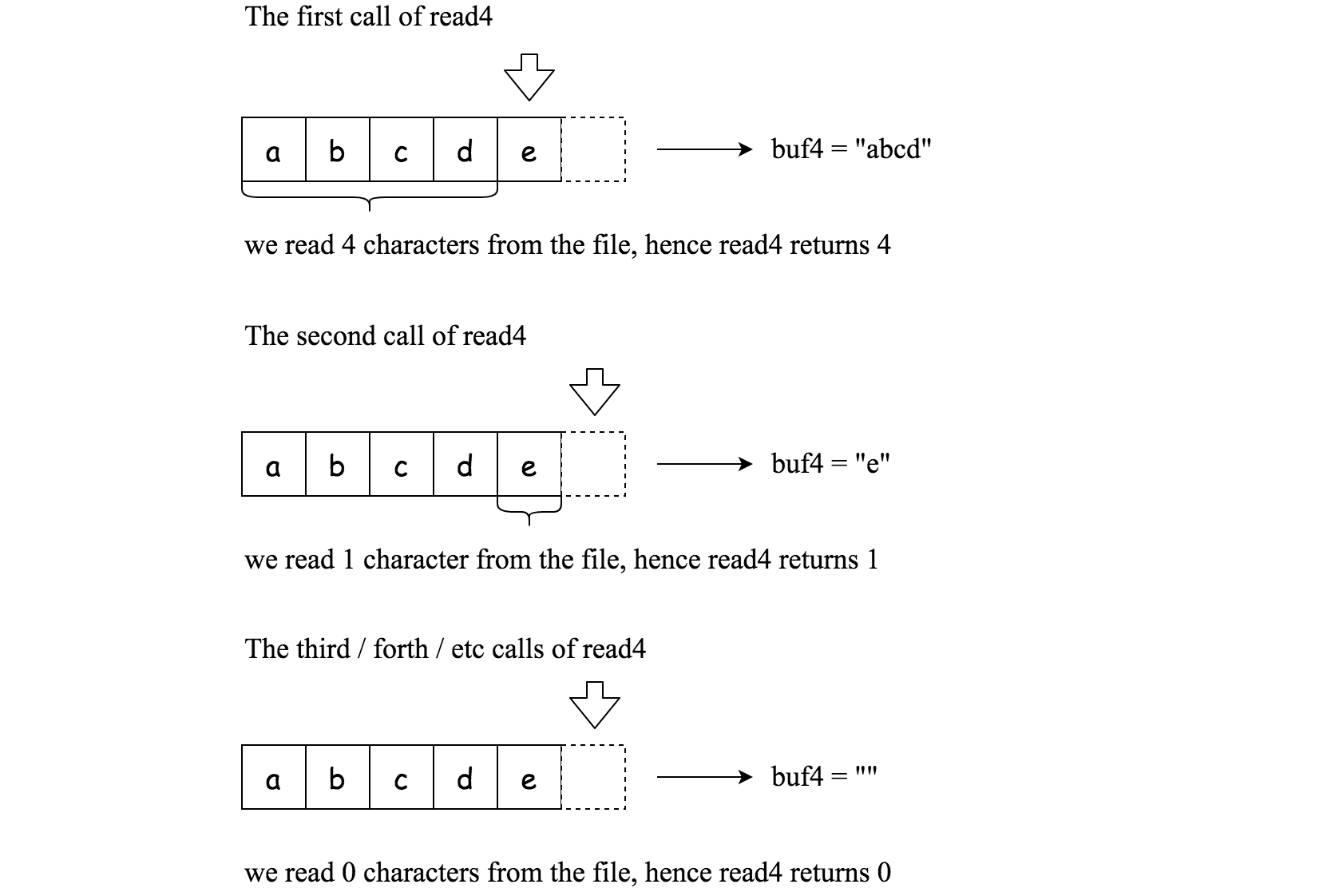
下列是一些使用 read4 的例子:
File file("abcde"); // 文件名为 "abcde",初始文件指针 (fp) 指向 'a'
char[] buf4 = new char[4]; // 创建一个缓存区使其能容纳足够的字符
read4(buf4); // read4 返回 4。现在 buf4 = "abcd",fp 指向 'e'
read4(buf4); // read4 返回 1。现在 buf4 = "e",fp 指向文件末尾
read4(buf4); // read4 返回 0。现在 buf4 = "",fp 指向文件末尾read 方法:
- 通过使用
read4方法,实现read方法。该方法可以从文件中读取 个字符并将其存储到缓存数组buf中。您 不能 直接操作file。 - 返回值为实际读取的字符。
read 的定义:
参数类型: char[] buf, int n
返回类型: int注意: buf[] 是目标缓存区不是源缓存区,你需要将结果写入 buf[] 中。
要求:返回实际读取的字符数。
说明:
- 你 不能 直接操作该文件,文件只能通过
read4获取而 不能 通过read。 read函数可以被调用 多次。- 请记得 重置 在 Solution 中声明的类变量(静态变量),因为类变量会在多个测试用例中保持不变,影响判题准确。
- 你可以假定目标缓存数组
buf保证有足够的空间存下 个字符。 - 保证在一个给定测试用例中,
read函数使用的是同一个buf。 - 。
file由英语字母和数字组成。- 。
- 。
示例:
- 示例 1:
输入:file = "abc", queries = [1,2,1]
输出:[1,2,0]
解释:测试用例表示以下场景:
File file("abc");
Solution sol;
sol.read(buf, 1); // 调用 read 方法后,buf 应该包含 "a"。我们从文件中总共读取了 1 个字符,所以返回 1。
sol.read(buf, 2); // 现在 buf 应该包含 "bc"。我们从文件中总共读取了 2 个字符,所以返回 2。
sol.read(buf, 1); // 我们已经到达文件的末尾,不能读取更多的字符。所以返回 0。
假设已经分配了 buf,并保证有足够的空间存储文件中的所有字符。- 示例 2:
输入:file = "abc", queries = [4,1]
输出:[3,0]
解释:测试用例表示以下场景:
File file("abc");
Solution sol;
sol.read(buf, 4); // 调用 read 方法后,buf 应该包含 "abc"。我们从文件中总共读取了 3 个字符,所以返回 3。
sol.read(buf, 1); // 我们已经到达文件的末尾,不能读取更多的字符。所以返回 0。解题思路
思路 1:缓存 + 多次调用处理
思路 1:算法描述
这道题与 0157 题的区别在于 read 方法会被 多次调用,因此需要维护一个内部缓冲区来保存上次调用 read4 时多读取的字符。
核心问题:
- 假设第一次调用
read(buf, 2),read4读取了 4 个字符,但只需要 2 个,剩余 2 个字符需要保存。 - 第二次调用
read(buf, 3)时,应该先使用上次剩余的 2 个字符,再调用read4读取新字符。
算法步骤:
- 使用实例变量
self.buffer保存上次多读取的字符。 - 使用实例变量
self.buffer_ptr和self.buffer_count记录缓冲区的读取位置和有效字符数。 - 每次调用
read时:- 先从内部缓冲区读取字符。
- 如果缓冲区字符不够,调用
read4读取新字符。 - 将字符复制到目标缓冲区,直到读取 个字符或文件结束。
思路 1:代码
# The read4 API is already defined for you.
# def read4(buf4: List[str]) -> int:
class Solution:
def __init__(self):
# 内部缓冲区,保存上次多读取的字符
self.buffer = [''] * 4
self.buffer_ptr = 0 # 缓冲区读取指针
self.buffer_count = 0 # 缓冲区有效字符数
def read(self, buf: List[str], n: int) -> int:
total = 0 # 已读取的字符总数
while total < n:
# 如果缓冲区为空,调用 read4 读取新字符
if self.buffer_ptr == self.buffer_count:
self.buffer_count = read4(self.buffer)
self.buffer_ptr = 0
# 如果读到文件末尾,结束
if self.buffer_count == 0:
break
# 从缓冲区复制字符到目标缓冲区
while total < n and self.buffer_ptr < self.buffer_count:
buf[total] = self.buffer[self.buffer_ptr]
total += 1
self.buffer_ptr += 1
return total思路 1:复杂度分析
- 时间复杂度:,其中 是需要读取的字符数。每个字符最多被处理一次。
- 空间复杂度:,只使用了固定大小的内部缓冲区。