0.3 算法复杂度
0.3 算法复杂度
---1. 算法复杂度简介
算法复杂度(Algorithm complexity):用于衡量算法在输入规模为 时所需的时间和空间资源。
这里的 问题规模 ,指的是算法输入的数据量。不同类型的算法, 的具体含义也有所不同:
- 排序算法中, 表示待排序元素的数量;
- 查找算法中, 表示查找范围的大小(如数组长度、字符串长度等);
- 图论算法中, 可以指节点数或边数,具体视问题而定;
- 二进制相关算法中, 通常指二进制的位数。
一般来说,输入规模越大,算法的计算成本也会随之增加;而当输入规模相近时,计算成本也会比较接近。
「算法分析」的核心目标是优化算法,使其 运行时间更短、内存占用更小。分析算法时,主要从运行时间和空间使用两个方面入手。常见的分析方法有两种:
- 事后统计:将不同算法分别实现并运行,通过实际测量运行时间和内存占用来比较优劣。
- 预先估算:在算法设计阶段,根据算法的步骤,理论上估算其运行时间和空间消耗,并进行比较。
实际应用中,我们更倾向于采用预先估算的方法,因为事后统计不仅工作量大,而且同一算法在不同编程语言和硬件环境下的表现差异较大。
采用预先估算时,我们通常不考虑编程语言、计算机运行速度等外部因素,关注的是算法随问题规模增长时的资源消耗趋势。
2. 时间复杂度
2.1 时间复杂度简介
时间复杂度(Time Complexity):用于衡量算法在输入规模为 时的运行时间,通常记作 。
时间复杂度的本质,是统计算法中 基本操作 的执行次数。也就是说,时间复杂度与算法中基本操作的数量成正比。
- 基本操作:指的是在常数时间内可以完成的语句,其执行时间与操作数的大小无关。
举例来说,两个小整数相加,所需时间不会因为数字位数的不同而变化,因此属于基本操作。但如果操作数非常大,运算时间会随位数增加而增长,这时整体加法就不再是基本操作,应将每一位的加法视为基本操作。
下面通过一个具体例子来演示时间复杂度的计算方法。
def find_max(arr):
max_val = arr[0] # 1 次操作
for i in range(len(arr)): # n 次循环
if arr[i] > max_val: # n 次比较
max_val = arr[i] # 最多 n 次赋值
return max_val # 1 次操作在上述例子中,基本操作总共执行了 次,因此可以用 表示其操作次数。
时间复杂度分析如下:
- 当 足够大时, 是主要影响项,常数 可以忽略不计。
- 由于我们关注的是随规模增长的趋势,常数系数 也可以省略。
- 因此,该算法的时间复杂度为 。这里的 表示渐近符号,强调 与 成正比。
所谓「算法执行时间的增长趋势」,实际上就是用类似 这样的渐近符号,来简洁地描述算法随输入规模变化时的资源消耗情况。
2.2 渐近符号
时间复杂度通常记作 ,称为 渐近时间复杂度(Asymptotic Time Complexity),用于描述当问题规模 趋近于无穷大时,算法运行时间的增长趋势。我们常用渐近符号(如 、、 等)来表达这种增长关系。渐近时间复杂度只关注主导项,忽略常数和低阶项,从而简洁地反映算法的本质效率。
渐近符号(Asymptotic Symbol):一类数学符号,用于描述函数(如算法运行时间或空间)随输入规模增长时的变化速度。在算法分析中,常用的渐近符号有大 (上界)、大 (下界)、大 (紧确界),它们帮助我们以统一的方式比较不同算法的效率。
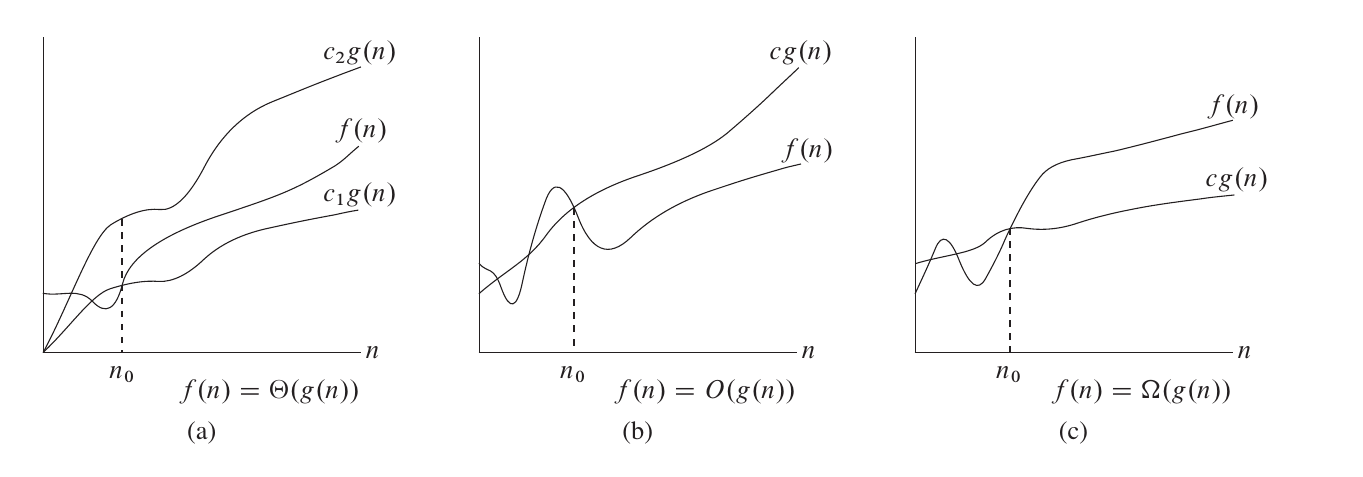
2.2.1 渐近上界符号
渐近上界符号 :用于描述算法运行时间的上限,通常反映算法在最坏情况下的性能。
数学定义:设 和 为两个函数,如果存在正常数 和 ,使得对所有 ,都有 ,则称 。
直观理解: 表示「算法的运行时间至多为 的某个常数倍」,即不会比 增长得更快。
示例:
- 如果 ,则 。
- 如果 ,则 。
- 如果 ,则 。
2.2.2 渐近下界符号
渐近下界符号 :用于描述算法运行时间的下界,通常反映算法在最优情况下的性能。
数学定义:设 和 为两个函数,如果存在正常数 和 ,使得对所有 ,都有 ,则称 。
直观理解: 表示「算法的运行时间至少不会低于 的某个常数倍」,即增长速度不慢于 。
示例:
- 如果 ,则 。
- 如果 ,则 。
- 如果 ,则 。
2.2.3 渐近紧确界符号
渐近紧确界符号 :用于描述算法运行时间的精确数量级,即算法在最好和最坏情况下的增长速度都与 保持一致。
数学定义:设 和 为两个函数,如果存在正常数 及 ,使得对所有 ,都有 ,则称 。
直观理解: 表示「算法运行时间与 同阶」,即上下界都为 的常数倍。
示例:
- 如果 ,则 。
- 如果 ,则 。
- 如果 ,则 。
2.3 时间复杂度计算
渐近符号用于描述函数的上界、下界,以及算法执行时间随问题规模增长的趋势。
在分析时间复杂度时,我们通常使用 符号来表示算法的上界,因为实际应用中更关注算法在最坏情况下的表现。
那么,如何具体计算时间复杂度呢?
一般来说,计算时间复杂度可以分为以下几个步骤:
- 确定基本操作:找出算法中执行次数最多的语句,通常是最内层循环的核心操作。
- 估算执行次数:只关注基本操作的最高阶项,忽略常数系数和低阶项。
- 用大 O 符号表示:将上一步得到的数量级用 符号表示出来。
在计算时间复杂度时,还需注意以下两条常用原则:
加法原则:多个代码块顺序执行时,总时间复杂度等于其中最大的那一个。
即如果 ,,,则 。
乘法原则:循环嵌套时,总时间复杂度等于各层复杂度的乘积。
即如果 ,,,则 。
下面通过具体实例来说明各种常见时间复杂度的计算方法。
2.3.1 常数时间
没有循环和递归的算法,时间复杂度通常为 。
def get_first_element(arr):
return arr[0] # 直接返回第一个元素
def add_two_numbers(a, b):
return a + b # 简单的加法运算上述代码中,每个函数都只执行常数次操作,时间复杂度为 。
2.3.2 线性时间
单层循环遍历 个元素的算法,时间复杂度为 。
def find_max(arr):
max_val = arr[0]
for num in arr: # 遍历数组中的每个元素
if num > max_val:
max_val = num
return max_val
def sum_array(arr):
total = 0
for num in arr: # 遍历数组中的每个元素
total += num
return total上述代码中,每个函数都只遍历数组一次,时间复杂度为 。
2.3.3 平方时间
两层嵌套循环,每层执行 次操作的算法,时间复杂度为 。
def bubble_sort(arr):
n = len(arr)
for i in range(n): # 外层循环
for j in range(n - 1): # 内层循环
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
def find_all_pairs(arr):
pairs = []
for i in range(len(arr)): # 外层循环
for j in range(len(arr)): # 内层循环
pairs.append((arr[i], arr[j]))
return pairs上述代码中,每个函数都包含两层嵌套循环,总操作次数为 ,时间复杂度为 。
2.3.4 对数时间
每次操作将问题规模缩小一半的算法,如「二分查找」和「分治算法」,时间复杂度为 。
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
def power_of_two(n):
count = 0
while n > 1:
n = n // 2 # 每次除以2
count += 1
return count上述代码中,每次将问题规模缩小一半,循环次数为 ,时间复杂度为 。
2.3.5 线性对数时间
线性对数一般出现在排序算法中,例如「快速排序」、「归并排序」、「堆排序」等,时间复杂度为 。
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = merge_sort(arr[:mid]) # 递归处理左半部分
right = merge_sort(arr[mid:]) # 递归处理右半部分
return merge(left, right) # 合并两个有序数组
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result上述代码中,merge_sort 函数采用了分治思想,每次递归将数组一分为二,递归深度为 层,每层处理 个元素,整体的时间复杂度为 。
2.3.6 指数时间
指数时间复杂度 通常出现在每一步都存在两种选择、递归分支成倍增长的算法中,如递归斐波那契、子集枚举等,时间复杂度为 。
def fibonacci_recursive(n):
if n <= 1:
return n
return fibonacci_recursive(n-1) + fibonacci_recursive(n-2)
def generate_subsets(arr):
def backtrack(start, current):
result.append(current[:])
for i in range(start, len(arr)):
current.append(arr[i])
backtrack(i + 1, current)
current.pop()
result = []
backtrack(0, [])
return result上述代码中,fibonacci_recursive 函数每次递归都会分裂成两个子问题,递归树的节点总数为 ,因此时间复杂度为 。generate_subsets 函数通过回溯法枚举所有子集,每个元素有选或不选两种选择,子集总数为 ,所以整体时间复杂度也是 。
2.3.7 阶乘时间
阶乘时间 通常出现在需要枚举所有排列或组合的算法中,如全排列、旅行商问题暴力解法等。随着输入规模 的增加,算法的执行次数以阶乘级别增长,计算量极大,几乎
无法处理较大的输入规模。
def generate_permutations(arr):
def backtrack(start):
if start == len(arr):
result.append(arr[:])
return
for i in range(start, len(arr)):
arr[start], arr[i] = arr[i], arr[start] # 交换
backtrack(start + 1) # 递归
arr[start], arr[i] = arr[i], arr[start] # 恢复
result = []
backtrack(0)
return result上述代码中,generate_permutations 函数通过回溯法枚举所有排列。每一层递归会将当前位置与后续每个元素交换,递归深度为 层。第 1 层有 种选择,第 2 层有 种选择,依此类推,总共 种排列,因此时间复杂度为 。
2.3.8 时间复杂度对比
常见时间复杂度从小到大排序: < < < < < < < <
| 时间复杂度 | 输入规模 | 实际应用 | ||
|---|---|---|---|---|
| 数组访问、哈希表查找 | ||||
| 二分查找、平衡树操作 | ||||
| 线性搜索、数组遍历 | ||||
| 快速排序、归并排序 | ||||
| 冒泡排序、选择排序 | ||||
| 递归斐波那契 | ||||
| 全排列 |
2.4 最佳、最坏、平均时间复杂度
由于同一算法在不同输入下的表现可能差异很大,我们通常从三个角度分析时间复杂度:
- 最佳时间复杂度:最理想输入下的时间复杂度
- 最坏时间复杂度:最差输入下的时间复杂度
- 平均时间复杂度:随机输入下的期望时间复杂度
示例:在数组中查找目标值
def find(nums, val):
for i in range(len(nums)):
if nums[i] == val:
return i
return -1- 最佳情况:目标值在数组开头,时间复杂度
- 最坏情况:目标值不存在,需要遍历整个数组,时间复杂度
- 平均情况:假设目标值等概率出现在任意位置,平均时间复杂度
实际应用:通常使用 最坏时间复杂度 作为算法性能的衡量标准,因为它能保证算法在任何输入下的性能上限。只有在不同情况下的时间复杂度存在量级差异时,才需要区分三种情况。
3. 空间复杂度
3.1 空间复杂度简介
空间复杂度(Space Complexity):在问题的输入规模为 的条件下,算法所占用的空间大小,可以记作为 。一般将 算法的辅助空间 作为衡量空间复杂度的标准。
空间复杂度的渐近符号表示方法与时间复杂度相同,可以表示为 ,表示算法空间占用随问题规模 的增长趋势。
相对于算法的时间复杂度计算来说,算法的空间复杂度更容易计算。空间复杂度的计算主要包括局部变量占用的存储空间和递归栈空间两个部分。
3.2 空间复杂度计算
空间复杂度的计算主要考虑算法运行过程中额外占用的空间,包括局部变量和递归栈空间。
3.2.1 常数空间
def algorithm(n):
a = 1
b = 2
res = a * b + n
return res上述代码中,只使用了固定数量的变量,因此空间复杂度为 。
3.2.2 线性空间
def algorithm(n):
if n <= 0:
return 1
return n * algorithm(n - 1)上述代码中,递归深度为 ,需要 的栈空间。
3.2.3 常见空间复杂度
常见空间复杂度从小到大排序: < < < <
4. 总结
「算法复杂度」 包括 「时间复杂度」 和 「空间复杂度」,用于衡量算法在输入规模 增大时的资源消耗情况。通常使用渐近符号(如 符号)来描述算法复杂度的增长趋势。
常见的时间复杂度有:、、、、、、、。
常见的空间复杂度有:、、、。
参考资料
- 【书籍】数据结构(C++ 语言版)- 邓俊辉 著
- 【书籍】算法导论 第三版(中文版)- 殷建平等 译
- 【书籍】算法艺术与信息学竞赛 - 刘汝佳、黄亮 著
- 【书籍】数据结构(C 语言版)- 严蔚敏 著
- 【书籍】趣学算法 - 陈小玉 著
- 【文章】复杂度分析 - 数据结构与算法之美 王争
- 【文章】算法复杂度(时间复杂度+空间复杂度)
- 【文章】算法基础 - 复杂度 - OI Wiki
- 【文章】图解算法数据结构 - 算法复杂度 - LeetBook - 力扣