4.1 字符串基础
4.1 字符串基础
---1. 字符串简介
字符串(String):简称为串,由零个或多个字符组成的有限序列,常记为 。
1.1 字符串常见概念
- 字符串名称:如 。
- 字符串的值:字符序列 ,通常用双引号括起来。
- 字符变量:字符串中每个位置的字符(),可以是字母、数字或其他字符, 表示其位置。
- 字符串长度:字符个数 。
- 空串:长度为 的字符串,记为
""。 - 子串:字符串中任意连续字符组成的序列。特殊子串包括 前缀(从第 位起,长度为 )和 后缀(以 结尾,长度为 )。
- 主串:包含子串的字符串。
举个例子来说明一下:
str = "Hello World"在示例代码中, 是一个字符串的变量名称,Hello World 则是该字符串的值,字符串的长度为 。该字符串的表示如下图所示:

字符串与数组相似,都使用 名称[下标] 方式访问元素。
1.2 字符串的特点
- 数据元素都是字符,结构简单但规模可能很大
- 常作为整体处理,操作对象是整个字符串或子串
- 经常需要处理多个字符串间的操作(连接、比较等)
1.3 字符串问题分类
根据字符串的特点,我们可以将字符串问题分为以下几种:
- 字符串匹配问题
- 子串相关问题
- 前缀 / 后缀相关问题
- 回文串相关问题
- 子序列相关问题
2. 字符串的比较
2.1 字符串的比较操作
数字之间的大小比较非常直观,例如 。而字符串的大小比较则稍显复杂,其本质是根据字符在字符串中的排列顺序和字符编码来决定的。
以 str1 = "abc" 和 str2 = "acc" 为例,二者的首字母都是 ,但第二个字母 比 靠前,因此 ,所以 "abc" < "acc",即 。
字符串的比较实际上是逐字符比较其「字符编码」——即每个字符在字符集中的编号。
判断两个字符串是否相等,需要满足以下两个条件:
- 两个字符串的长度相等;
- 两个字符串对应位置上的每个字符都相同。
如果要比较两个字符串的大小,可以按照如下规则进行:
- 从第 个字符开始,依次比较对应位置上的字符编码:
- 如果 的字符编码等于 ,则继续比较下一位;
- 如果 的字符编码小于 ,则 ,如
"abc" < "acc"; - 如果 的字符编码大于 ,则 ,如
"bcd" > "bad"。
- 如果某一字符串已比较到末尾,另一个字符串还有剩余字符:
- 如果 ,则 ,如
"abc" < "abcde"; - 如果 ,则 ,如
"abcde" > "abc"。
- 如果 ,则 ,如
- 如果所有字符都相等且长度也相同,则 ,如
"abcd" == "abcd"。
基于上述规则,可以实现一个 strcmp 方法,约定如下返回值:
- 时,返回 ;
- 时,返回 ;
- 时,返回 。
strcmp 方法的实现如下:
def strcmp(str1, str2):
"""
比较两个字符串的大小。
返回值:
-1:str1 < str2
0:str1 == str2
1:str1 > str2
"""
# 逐字符比较
i = 0
while i < len(str1) and i < len(str2):
c1 = ord(str1[i])
c2 = ord(str2[i])
if c1 < c2:
return -1 # str1 当前字符小于 str2
elif c1 > c2:
return 1 # str1 当前字符大于 str2
i += 1
# 如果前面都相等,比较长度
if len(str1) < len(str2):
return -1 # str1较短
elif len(str1) > len(str2):
return 1 # str1较长
else:
return 0 # 完全相等其实,判断字符串大小最直观的例子就是「查英语词典」。在词典中,前面的单词总是比后面的单词小。我们可以把词典里的每个单词看作一个字符串,查找单词的过程本质上就是按照字符串大小进行比较和排序。
2.2 字符串的字符编码
前面我们提到了字符编码,这里简要介绍几种常见的字符串字符编码标准。
最早,计算机采用 ASCII 编码来表示字符。ASCII 编码表包含 个字符,涵盖了英文字母(大小写)、数字及常用符号。每个字符对应唯一的编码值,例如大写字母 的编码是 ,小写字母 的编码是 。
然而,ASCII 编码只能满足英文等西方语言的需求,无法表示中文等其他语言字符。为支持中文,我国先后制定了 GB2312、GBK、GB18030 等中文编码标准,将常用汉字纳入编码体系。但全球有上百种语言,各国标准不一,导致编码冲突频发。为解决这一问题,国际上推出了统一的 Unicode 编码标准。
Unicode 能够为世界上所有文字和符号分配唯一编码。实际存储和传输时,Unicode 最常用的实现方式是 UTF-8 编码。UTF-8 会根据字符的不同,将每个 Unicode 字符编码为 个字节:常用英文字母通常占 个字节,汉字一般占 个字节。
3. 字符串的存储结构
字符串的存储结构与线性表类似,主要分为「顺序存储结构」和「链式存储结构」两类。
3.1 字符串的顺序存储结构
顺序存储结构是指用一组地址连续的存储单元,依次存放字符串中的各个字符。通常为每个字符串变量分配一个固定长度的存储空间,常见实现方式是定长数组。
如下图所示:
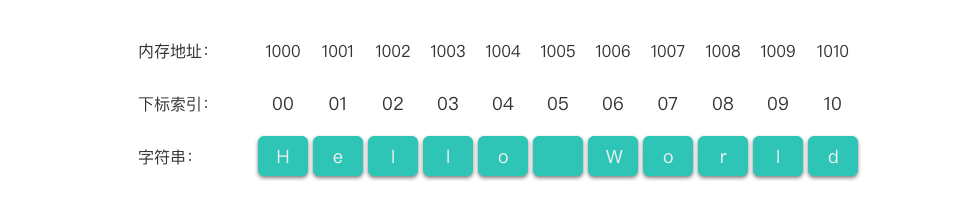
在顺序存储结构中,每个字符都有唯一的下标索引,索引从 开始,到 结束。每个下标对应一个字符元素。
顺序存储的字符串支持随机访问,可以通过下标直接定位和访问任意字符,效率高,操作便捷。
3.2 字符串的链式存储结构
链式存储结构是用线性链表来存储字符串。每个链节点包含一个用于存放字符的 字段,以及指向下一个节点的指针 ,从而将所有字符串联起来。
链式存储结构中,每个节点可以存放一个或多个字符。常见的做法是每个节点存放 个或 个字符,以减少空间浪费。当节点存放 个字符时,如果字符串长度不是 的倍数,最后一个节点未用满的部分可用 # 或其他特殊字符补齐。
如下图所示:

链式存储结构通过指针将分散的存储单元连接起来,逻辑上形成一个完整的字符串。其优点是插入、删除操作灵活,但随机访问效率较低。
3.3 各语言中的字符串实现
- C 语言:字符串以字符数组形式存储,并以空字符
\0结尾标识结束。相关操作函数在string.h头文件中。 - C++ 语言:既支持 C 风格字符串,也提供了功能更强的
string类,极大简化了字符串操作。 - Java 语言:标准库中提供了
String类,专门用于字符串处理。 - Python 语言:字符串由
str类型对象表示,属于不可变类型。即一旦创建,字符串的内容和长度都无法更改或删除。
4. 字符串匹配问题
字符串匹配(String Matching),又称模式匹配(Pattern Matching),指的是在一个主串 (文本串)中查找某个子串 (模式串)的位置。
字符串匹配是字符串处理领域中最核心的问题之一。根据需要查找的模式串数量,字符串匹配问题可分为「单模式串匹配」和「多模式串匹配」两大类。
4.1 单模式串匹配问题
单模式匹配问题(Single Pattern Matching):给定一个文本串 和一个模式串 ,要求找出 在 中所有出现的位置。
4.1.1 问题描述
单模式串匹配问题是字符串匹配的基础问题,其形式化定义如下:
- 输入:文本串 ,模式串
- 输出:所有满足 的位置
- 目标:高效地找到所有匹配位置
4.1.2 主要算法介绍
针对单模式串匹配,常见的算法可根据其在文本中搜索模式串的方式分为以下几类:
朴素算法
- Brute Force 算法(暴力匹配算法)
- 时间复杂度:
- 空间复杂度:
- 特点:简单直观,但效率较低
- 适用场景:模式串较短或对性能要求不高的场景
基于前缀搜索的方法
- KMP 算法(Knuth-Morris-Pratt 算法)
- 时间复杂度:
- 空间复杂度:
- 特点:利用失配信息避免重复比较,从前向后逐个读取文本字符
- 适用场景:对性能要求较高的场景
基于后缀搜索的方法
Boyer Moore 算法
- 时间复杂度:平均 ,最坏
- 空间复杂度:( 为字符集大小)
- 特点:从右到左比较,跳跃能力强
- 适用场景:模式串较长,字符集较小的场景
Horspool 算法
- 时间复杂度:平均 ,最坏
- 空间复杂度:
- 特点:BM算法的简化版本,实现简单
- 适用场景:需要简单实现的场景
Sunday 算法
- 时间复杂度:平均 ,最坏
- 空间复杂度:
- 特点:从左到右比较,跳跃能力强
- 适用场景:需要从左到右匹配的场景
基于子串搜索的方法
- Rabin Karp 算法
- 时间复杂度:平均 ,最坏
- 空间复杂度:
- 特点:使用滚动哈希,平均性能较好
- 适用场景:需要处理多个模式串或对哈希冲突不敏感的场景
4.1.3 算法复杂度对比
| 算法 | 预处理时间 | 匹配时间 | 空间复杂度 | 特点 |
|---|---|---|---|---|
| Brute Force | 简单直观 | |||
| Rabin Karp | 平均 ,最坏 | 滚动哈希 | ||
| KMP | 失配信息 | |||
| Boyer Moore | 平均 ,最坏 | 启发式跳跃 | ||
| Horspool | 平均 ,最坏 | BM简化版 | ||
| Sunday | 平均 ,最坏 | 从左到右 |
4.2 多模式串匹配问题
多模式匹配问题(Multi Pattern Matching):给定一个文本串 ,以及一组模式串 ,其中每个模式串 是由有限字母表组成的字符串 。目标是在文本串 中找出集合 中所有模式串 的全部出现位置。
4.2.1 问题描述
输入:一个长度为 的文本串 ,和若干模式串组成的集合 ,每个模式串长度为 。
输出:返回每个模式串 在 中所有出现的位置下标。
目标:高效地一次性找出所有模式串在文本串中的全部匹配位置。
简而言之,多模式串匹配问题要求:给定一个文本串和多个模式串,找出每个模式串在文本串中所有出现的位置。
4.2.2 主要算法介绍
针对多模式串匹配,最朴素的做法是对每个模式串分别进行 次单模式匹配(如 Brute Force、KMP 等),但这种方法在模式串数量较多时效率极低。为此,实际应用中常用更高效的多模式串匹配算法,主要包括以下三类:
多模式串匹配的高效算法主要可以归纳为三大类:前缀结构类、后缀结构类和哈希类。它们各自利用不同的数据结构和思想,实现对多个模式串的高效匹配。下面对主流方法进行梳理与融合说明:
前缀结构类方法
字典树(Trie)
- 时间复杂度:构建 ,单次查找
- 空间复杂度:
- 特点:支持高效的前缀匹配和批量字符串检索,结构直观,易于实现
- 适用场景:前缀匹配、字符串集合检索、词频统计等
AC 自动机
- 时间复杂度:构建 ,匹配
- 空间复杂度:
- 特点:在字典树基础上引入失败指针,结合 KMP 失配思想,可一次遍历文本高效匹配所有模式串
- 适用场景:多模式串精确匹配,如敏感词过滤、病毒特征检测等
后缀结构类方法
后缀数组
- 时间复杂度:构建 ,查找
- 空间复杂度:
- 特点:支持后缀的快速排序和二分查找,适合子串定位和重复子串分析,实现相对简单
- 适用场景:子串查找、最长重复子串、最长公共子串等
后缀树
- 时间复杂度:构建 (理论),实际实现较复杂
- 空间复杂度:,但常数较大
- 特点:支持复杂的字符串分析,能高效解决多种字符串问题,但实现难度高、空间消耗大
- 适用场景:复杂的字符串分析、需要多种子串关系查询的场景(实际多用后缀数组替代)
哈希与子串搜索类方法
- Rabin-Karp 算法
- 时间复杂度:平均 ,最坏
- 空间复杂度:
- 特点:利用滚动哈希批量比对多个模式串,平均性能较好,但哈希冲突时退化
- 适用场景:需要处理多个模式串、对哈希冲突不敏感的场景
综上,实际应用中多模式串匹配常用 AC 自动机(高效且适用范围广)、字典树(适合前缀类问题)、后缀数组(适合后缀和子串分析)以及 Rabin-Karp(适合哈希批量比对)等方法。选择哪种算法,需根据具体问题规模、模式串数量、匹配需求等因素综合考虑。
4.2.3 算法复杂度对比
| 算法 | 预处理时间 | 匹配时间 | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|---|---|
| 字典树 | 稳定 | 前缀匹配、字符串集合操作 | |||
| AC 自动机 | 稳定 | 多模式串精确匹配 | |||
| 后缀数组 | 稳定 | 子串匹配、后缀相关操作 |
其中:
- 表示文本串长度
- 表示单个模式串长度
- 表示所有模式串的总长度
需要特别指出的是,绝大多数高效的多模式串匹配算法都依赖于一种基础数据结构: 字典树(Trie Tree)。其中,著名的 Aho-Corasick 自动机(AC 自动机)算法,正是将「KMP 算法」与
「字典树」结构结合的产物,也是目前多模式串匹配中最常用、最有效的算法之一。
因此,学习多模式匹配算法时,重点应掌握 字典树 及 AC 自动机算法 的原理与实现。
练习题目
参考资料
- 【书籍】数据结构(C 语言版)- 严蔚敏 著
- 【书籍】大话数据结构 - 程杰 著
- 【书籍】数据结构教程(第 3 版)唐发根 著
- 【书籍】数据结构与算法 Python 语言描述 - 裘宗燕 著
- 【书籍】柔性字符串匹配 - 中科院计算所网络信息安全研究组 译
- 【博文】字符串和编码 - 廖雪峰的官方网站
- 【文章】数组和字符串 - LeetBook - 力扣
- 【文章】字符串部分简介 - OI Wiki
- 【文章】解密 Python 中字符串的底层实现,以及相关操作 - 古明地盆 - 博客园